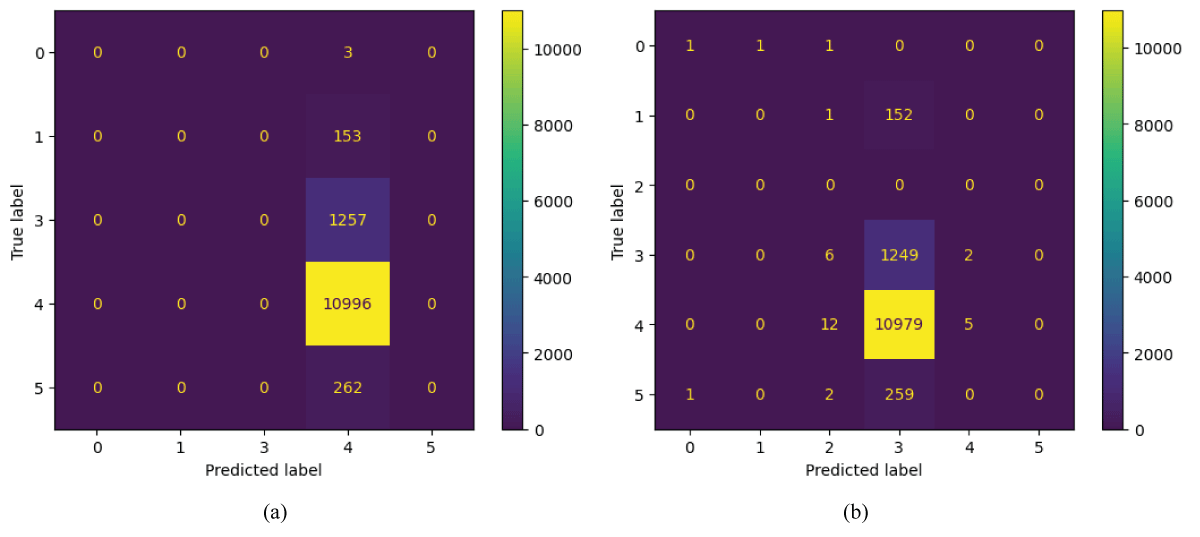
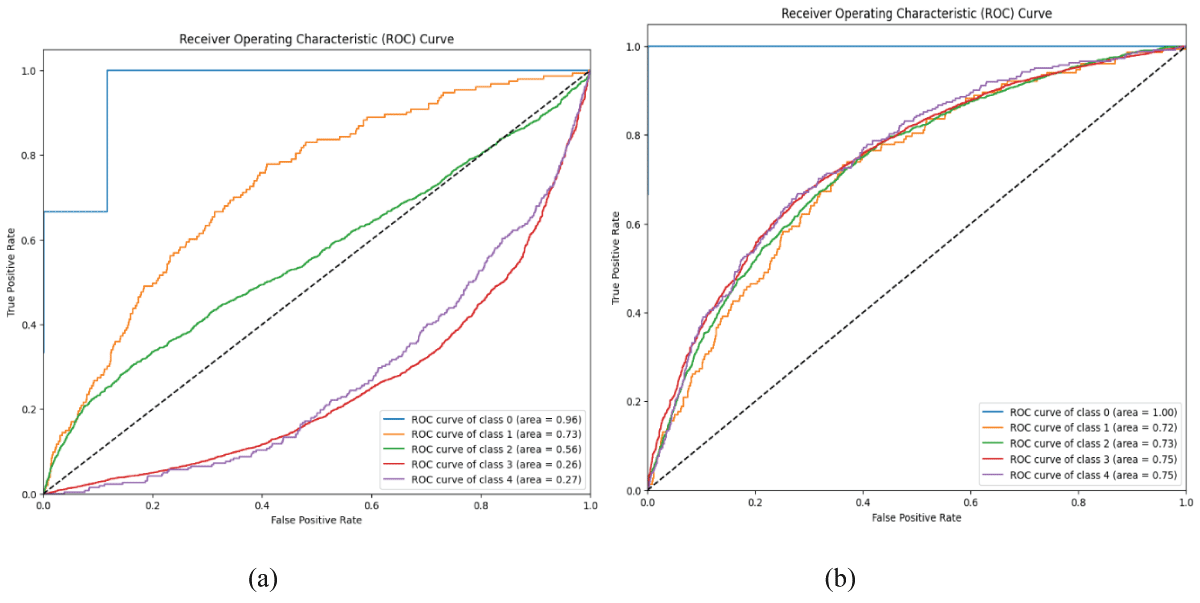
Abstract
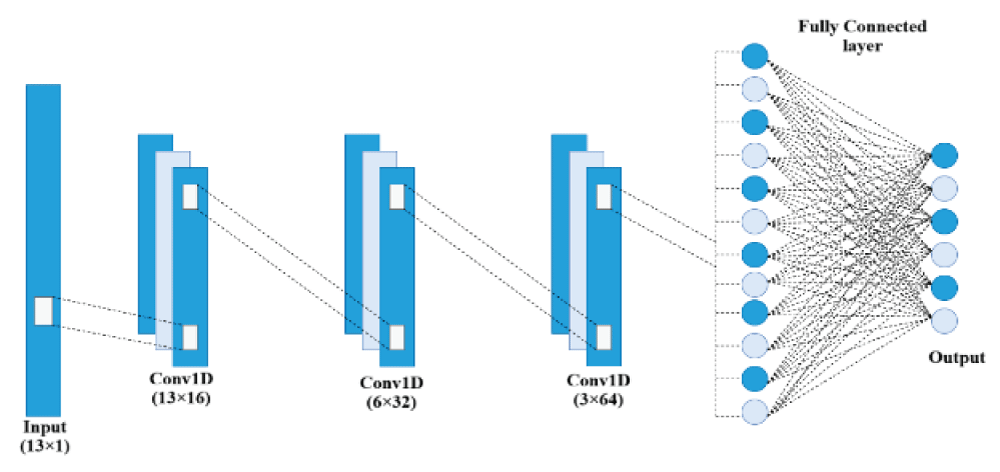
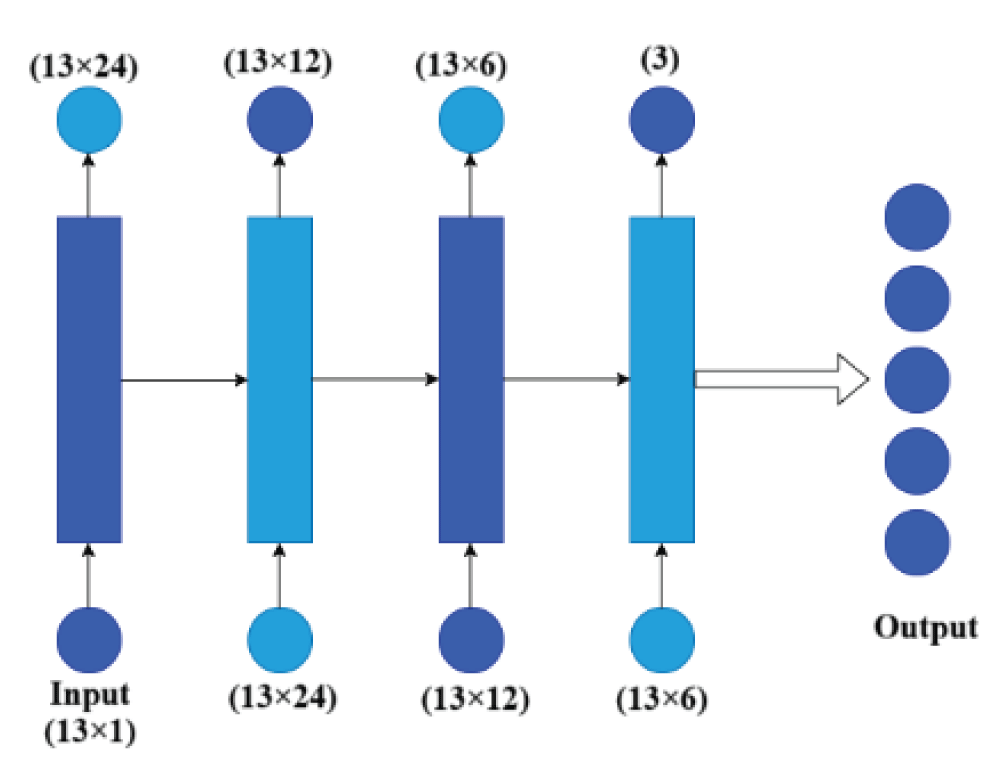
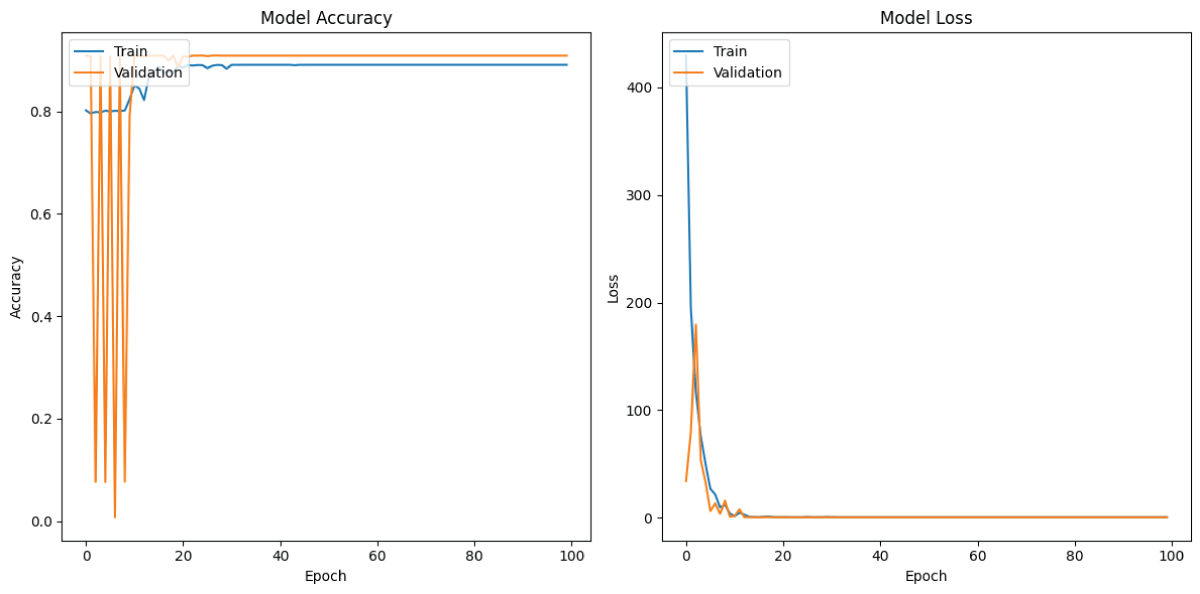
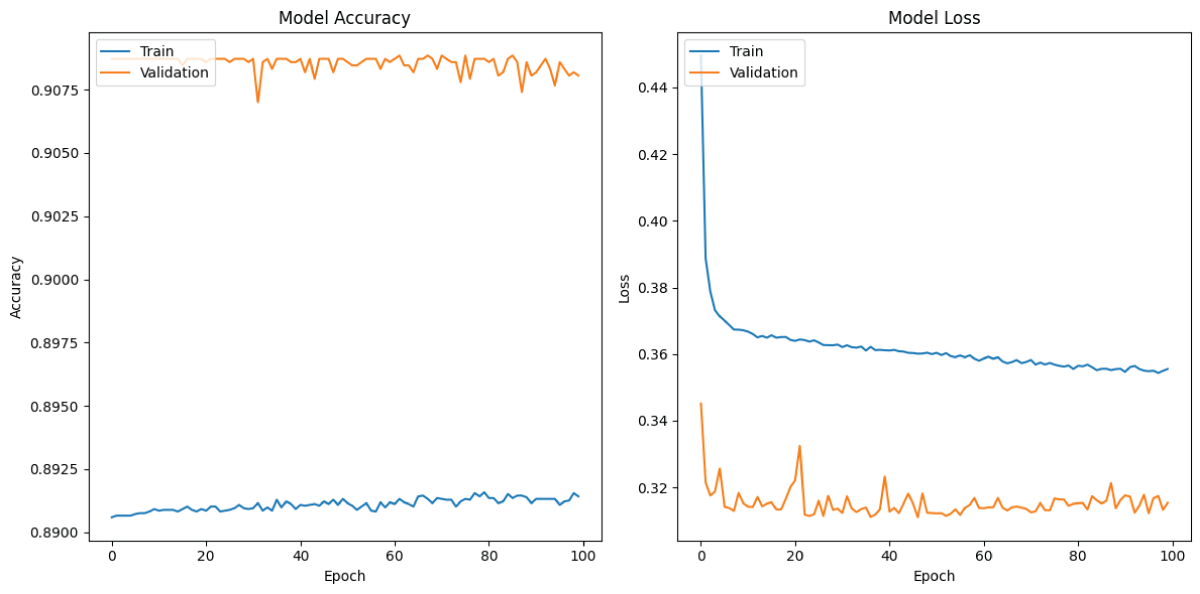
Audio signal classification plays a significant role in various real-world applications such as speech recognition, environmental sound analysis, and music genre identification. Traditional approaches often depend on manually extracted features, which may not capture the full complexity of audio data. This paper presents a deep learning-based method for automatic classification of audio signals using a One-Dimensional Convolutional Neural Network (1D-CNN) and a Recurrent Neural Network (RNN). The CNN model is utilized to extract spatial features from spectrogram representations, while the RNN model effectively captures temporal dependencies within the audio sequences. Both models were trained and evaluated on a labelled dataset, and their performance was compared using metrics such as accuracy, precision, probability of detection (POD), and F1-score. The experimental results demonstrate that CNN has achieved high classification accuracy compared to RNN, with CNN excelling at spatial feature extraction and RNN providing temporal feature learning. The proposed approach confirms that deep learning models can significantly enhance the performance and reliability of audio signal classification systems.